
Git basic concepts
- Git
I was using a Git GUI for quite a while now (Sourcetree mainly) and though the GUI is very convenient it also hides what is going on under the hood. Therefore, to strengthen my understanding I dug a little deeper into Git and start at the basic level. This article will cover what I have learned about the global workings of Git.
Commits
At its core Git is a collection of snapshots of the directory's contents. A commit is a pointer to a specific snapshot and basically, everything revolves around these commits.
Git stores files as blob objects. The snapshots reference the blob-objects that are in the directory and a commit references (aka is a pointer to) a snapshot. Simplified this would look something like this:
 This way of storing objects makes Git a very efficient system since a blob object can be referenced by multiple snapshots and Git doesn't have to store duplicates (which is the case with other version control systems). So the amount of needed storage is efficient but also the speed when switching branches.
This way of storing objects makes Git a very efficient system since a blob object can be referenced by multiple snapshots and Git doesn't have to store duplicates (which is the case with other version control systems). So the amount of needed storage is efficient but also the speed when switching branches.
So what will this look like when a change is made, like deleting a file, and this change is committed?
Obviously, a new commit is created and since every commit references its own specific snapshot a new snapshot is also created. This new snapshot will reference the blob objects representing the files that are part of the snapshot. To preserve commit history the second commit also references the first commit (which is now its parent commit).

Branches
So now we know about commits, let's introduce another important concept: branches. In short, a branch is a pointer to a certain commit. The default branch is often called MAIN, although you can name it whatever you want. And you can make as many branches as you want.
There is also a pointer called HEAD which points to the last commit of the current branch. The MAIN and HEAD can point to the same commit, but don't have to. This might sound really confusing but it might look like this:
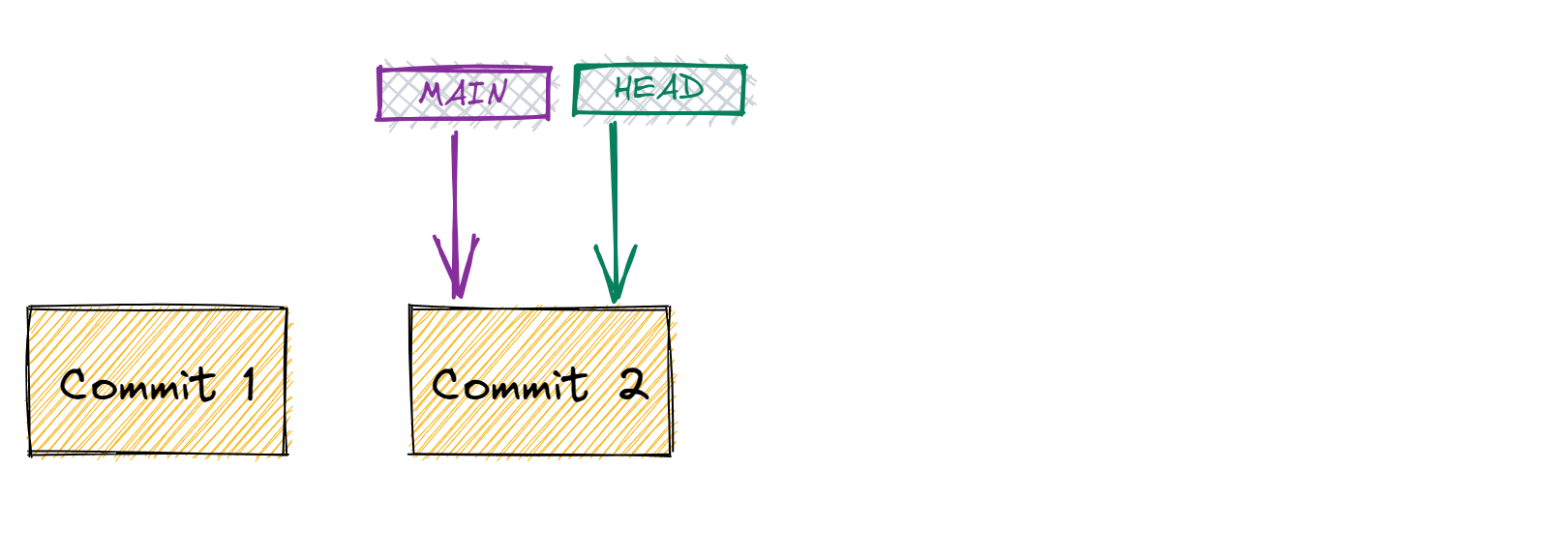
If I want to create a new branch to make some changes in isolation I can do this with branch. Let's say I want to create a branch called DEVELOP:
git branch DEVELOP
If a want to make this newly created branch the current branch I use checkout. Now the HEAD switches to this branch. Any commit will only affect the current branch.
git checkout DEVELOP
It's possible to create and switch branch with only one command:
git checkout -b DEVELOP
When we make a commit to the DEVELOP branch, the MAIN branch keeps it's pointer on the same commit, but the DEVELOP branch references the new commit and the HEAD moves along with it since DEVELOP is the current branch.
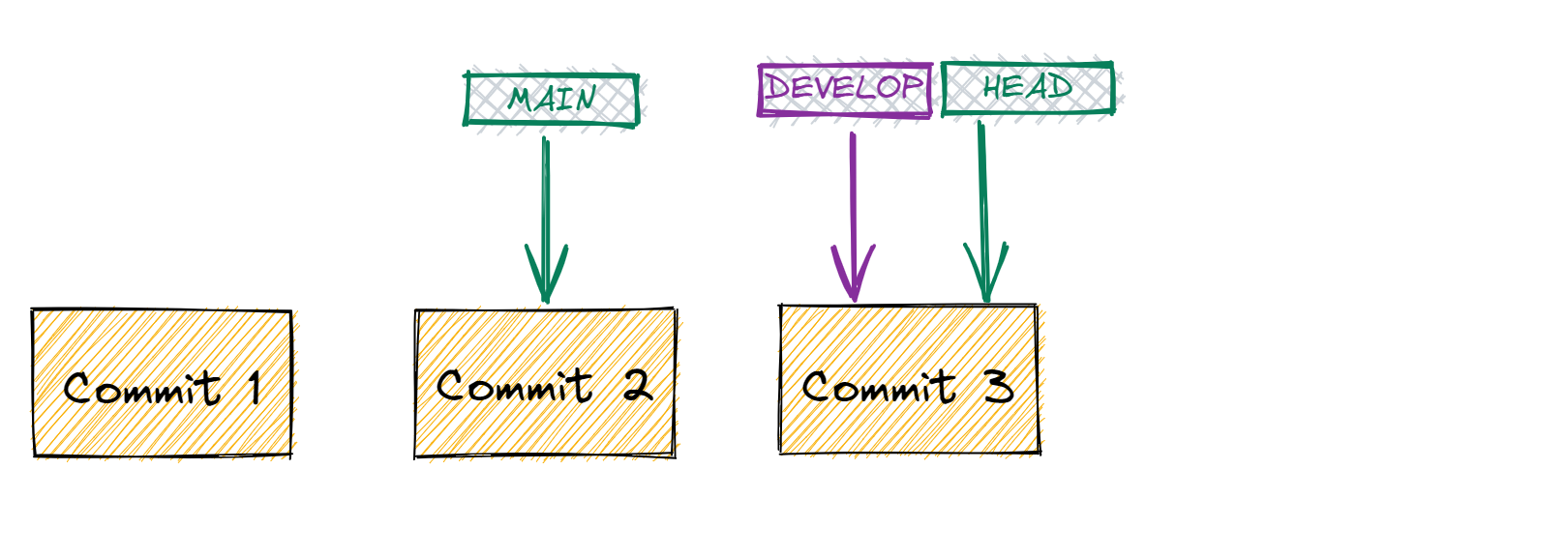
Connect branch to Remote repository
Part of the Git environment can be a Remote repository (see this article for more information). The new branch was created in the local environment and is only present there. If you want to work with a Remote repository the branch needs to be connected to an upstream branch:
git push --set-upstream origin DEVELOP
List of branches
To see what branches are available get a list of the branches:
git branches
To see remote branches as well add the -a flag.
git branches -a
Delete branches
To delete the DEVELOP branch:
git DEVELOP -d
If a branch can not be deleted, for example when the branch is not considered fully merged, you can use a forceful delete (notice the option is now capital -D).
git DEVELOP -D
Hopefully it's a bit clear how Git deals with changes under the hood. Now it's time to understand what the Git environment looks like.